A video of the presentation (in Greek) is also available.
An introduction to Kotlin Coroutines for Android
A video of the presentation (in Greek) is also available.
You can find info on what the SMS Retriever API is here. Chances are that reaching this page means you already know that. For some reasons the hash generation process described in the docs did not work for me. Probably it’s a Mac only issue or the implementation of the sha256sum function I installed with coreutils.
What worked for me is getting the hash from within the App. A helper class for this is provided in Google Samples project.
A Kotlin snippet that does the same can be found bellow.
fun getAppSignature(context: Context) = context.packageManager.getPackageInfo(context.packageName, PackageManager.GET_SIGNATURES)
.signatures.mapNotNull { hash(context.packageName, it.toCharsString()) }.firstOrNull()
private fun hash(packageName: String, signature: String) = try {
val messageDigest = MessageDigest.getInstance("SHA-256")
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.KITKAT) {
messageDigest.update("$packageName $signature".toByteArray(StandardCharsets.UTF_8))
}
var hashSignature = messageDigest.digest()
hashSignature = Arrays.copyOfRange(hashSignature, 0, 9)
var base64Hash = Base64.encodeToString(hashSignature, Base64.NO_PADDING or Base64.NO_WRAP)
base64Hash = base64Hash.substring(0, 11)
base64Hash
} catch (e: NoSuchAlgorithmException) {
null
}
Coroutines that fascinated devs from its early beta have graduated the experimental phase and are now stable. Coroutines provide a way to write asynchronous code sequentially making multithreaded programming more debuggable and maintainable. In this article I will try to guide you through the main features of Coroutines that make it so special.

The problem coroutines try to tackle is how to prevent our applications from blocking. Asynchronous or non-blocking programming is the new reality both on the client side to provide a fluid experience and on the server side for a more scalable architecture. There are several approaches to this problem including Threads, Callbacks, Futures/Promises and Reactive extensions.
Based on the concept of suspending functions coroutines approached the problem in a different way. One of the main advantages over competitive approaches is that the structure of the code is still sequential and easier to write. Coroutines are also light-weight and sometimes are wrongly marketed as “light-weight threads”. Coroutines have been around for decades and are popular in some other programming languages (e.g. Go). In fact the term was coined in 1958 by Melvin Conway (known for Conway’s Law).
Kotlin provides coroutine support at the language level but the functionality is delegated to libraries. Only one keyword is added to the core language, the suspend keyword. This article is based on kotlinx.coroutines, a coroutines library developed by JetBrains.
Let’s see an example to understand what a suspending function is. For this we will use the sequence function that allows us to build sequences.
fun main() {
val numbers = sequence {
println("one")
yield(1)
println("two")
yield(2)
println("three")
yield(3)
println("...done")
}
for (n in numbers) {
println("number = $n")
}
}
If we run the above the output is:
one
number = 1
two
number = 2
three
number = 3
...doneThe first time we call the function it runs up to line four and returns the value 1. The second call unlike what we know from standard functions start where we left (at line 5) and returns value 2 at line 7.
Each time we reach a yield function call the next sequence number is returned along with a Continuation “wrapping” the rest of the code in the function. At this point the function is suspended. When we call to get the next number, the Continuation is used to resume the function where we left.
This example should give you a feeling of how suspending functions behave. We will revisit this type of functions later in more detail.
To understand how easy it is to transform a synchronous code to asynchronous code we will start with a simple sequential program that performs some network calls. Network calls are one of the most common use cases that we want our code to be non-blocking since sometimes they need a non trivial amount of time.
Suppose we have two functions. One that calls Google and one that calls Wikipedia. The functions’ signatures are the following.
fun google(keyword: String): String
fun wikipedia(keyword: String): String
The implementation details are not important (actually the implementation is quite simplistic) but you can see the sample code at Sequential.kt
A sequential main function that calls the above could be the following.
fun main() {
val keyword = "Meetup"
val gResult = google(keyword)
val wResult = wikipedia(keyword)
println("Google replied: $gResult \n" +
"Wikipedia replied: $wResult")
}
To transform the above to asynchronous or to be more precise concurrent code all we have to do is wrap the asynchronous parts in an async function block and wait for the results with the await() function. Our main function will transform as follows.
fun main() = runBlocking {
val keyword = "Meetup"
launch (Dispatchers.Default) {
val gResult = async { google(keyword) }
val wResult = async { wikipedia(keyword) }
println("Google replied: ${gResult.await()} \n" +
"Wikipedia replied: ${wResult.await()}")
}
}
We will explain runBlocking and launch blocks later when we we talk about coroutine builders. The important thing to notice at this point is that the sequence of the statements remains unchanged and the complexity of the code structure has not increased much.
In more detail, the async function launches a coroutine and immediately returns a Deferred object. The execution does not block at this point.
When we later need the actual value we unwrap it with the await() function. The latter suspends the execution till the value is ready to be unwrapped. When the async block completes the execution is resumed and the value is unwrapped.
val gResult: Deferred<String> = async { google(keyword) }
//execution is not blocked with the async call
//...
val gResultStr: String = gResult.await()
//execution is suspended till the value is ready
We claimed at the beginning that coroutines are light-weight. To prove this try to run the code bellow.
fun main() = runBlocking {
repeat(1_000_000) { counter ->
launch {
print(" $counter")
}
}
}
The above launches one million coroutines and each one prints a counter. If we try the above with treads we will most likely get an out of memory exception, or in a really powerful machine we will experience a much much slower execution. You can try yourself by replacing launch with thread.
To understand how suspending functions work let’s start again with a sequential code example.
fun fetchJson(term: String): String { ... }
fun parseExtract(wikipediaJson: String): String { ... }
fun main() {
val terms = listOf("Kotlin", "Athens", "Meetup")
val extracts = mutableListOf<String>()
terms.forEach {
val json = fetchJson(it)
extracts += parseExtract(json)
}
extracts.forEach { println(it) }
}
We defined two functions. fetchJson that fetches a json from the network and parseExtract that parses the json.
To achieve something useful we chain the two. The output of fetchJson is the input of parseExtract. We run this block for a list of terms and we collect the results in a mutable list extracts.
We will try to use our own suspending function to make the above code concurrent. Before that let’s highlight some key points on suspending functions:
We will wrap fetchJson in an async block. This will force us to change the type of the parameter of parseExtract from String to Deferred<String>. To unwrap the json string from the Deferred object our function needs to call the await function, which is a suspend function. Do do so our function must be declared as suspending with the suspend modifier. The code changes as follows.
suspend fun parseExtract(wikipediaJson: Deferred<String>): String {
val wikipediaJsonString = wikipediaJson.await()
//...code that does the parsing and returns the extract
}
fun main() = runBlocking {
val terms = listOf("Kotlin", "Athens", "Meetup")
val extracts = mutableListOf<String>()
terms.forEach {
val json = async { fetchJson(it) }
extracts += parseExtract(json)
}
extracts.forEach { println(it) }
}
We notice again that the transformation did not change the structure of our code. If we decompile the code before and after the transformation using the javap command though we will notice that the suspend function declaration is much different.
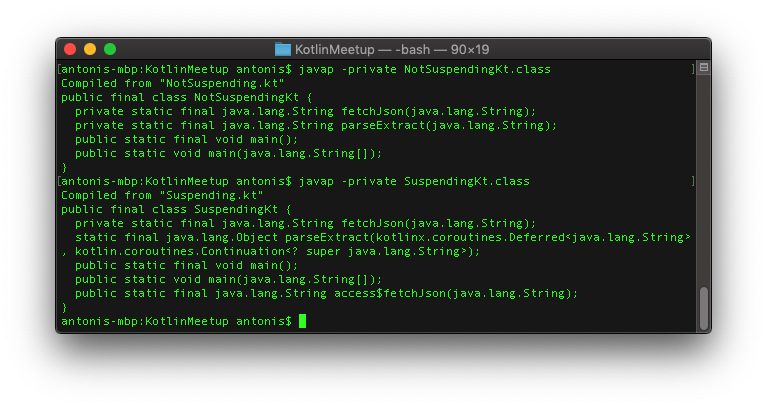
The most important thing to highlight is that the parseExtract function has an extra parameter hidden from our Kotlin code. This parameter is a Continuation and carries information for the function to resume after the suspension.
Coroutine Builders create a coroutine and provide a CoroutineScope.
runBlocking, launch and async are examples of coroutine builders we have used in the previous examples.
Let’s examine those in more detail:
The example bellow summarises the points above.
suspend fun main() {
// launch new coroutine and keep a reference to its Job
val job = GlobalScope.launch { //this is like a thread
delay(1000L)
println("World!")
}
println("Hello,")
job.join() // wait until child coroutine completes
}
Note that GlobalScope.launch creates a top-level coroutine just like a Thread.
Coroutines are launched in the scope of the operation we are performing. Every coroutine builder is an extension on CoroutineScope.
We can declare a scope using scoping function (like coroutineScope, withContext, etc).
In the following example coroutineScope builder declares a new scope.
fun main() = runBlocking {
launch {
delay(200L)
print("Kotlin ")
}
coroutineScope {
launch {
delay(300L)
print("Athens ")
}
delay(100L)
print("Hello ")
}
print("Meetup ")
}
The code above will output
Hello Kotlin Athens Meetup
This is because the coroutine scopes defined by launch and coroutineScope builder do not block the current thread while waiting for all children to complete.
CoroutineContext is an an optional parameter of all coroutine builders. It is inherited from the CoroutineScope if not defined.
launch {
// context of the parent
}
CoroutineContext includes a coroutine dispatcher that determines the execution thread.
launch(Dispatchers.Unconfined) {
// not confined -- will work with main thread
}
launch(Dispatchers.Default) {
// will get dispatched to DefaultDispatcher
}
launch(newSingleThreadContext("MyOwnThread")) {
// will get its own new thread
}
We can cancel a coroutine by keeping a reference to its job and calling the cancel() function.
val job = launch {
try {
repeat(1000) { counter ->
print(" $counter")
delay(50L)
}
} catch (e: CancellationException) {
print(" CancellationException\n")
}
}
delay(1000L)
job.cancel()
job.join()
As seen in the code above cancelation actually produces an exception (CancellationException) in suspension points. The code above handles this exception for logging purposes as part of the example. Normally you don’t have to handle those exceptions since they are handled by the coroutine machinery behind the scenes.
Another common scenario is cancelation with timeout.
try {
withTimeout(1000L) {
repeat(1000) { counter ->
print(" $counter")
delay(100L)
}
}
} catch (e: TimeoutCancellationException) {
print(" Timeout\n")
}

Parallelism is about the execution of multiple tasks at the same time. On the other hand concurrency tries to break down tasks which we don’t necessarily need to execute at the same time. Concurrency‘s primary goal is structure, not parallelism. Concurrency makes the use of parallelism easier since structure makes parallelism easier.
Launching coroutines in specific scopes and the father-child relationships that emerge define a more structured way to perform asynchronous tasks. This type of asynchronous code organisation is called structured concurrency.
We will use the google function from the previous examples to create a function that asynchronously googles a list of keywords. For each search a new coroutine is launched.
fun google(keyword: String): String { ... }
suspend fun google(keywords: List<String>) = coroutineScope {
for (keyword in keywords) {
println("Googling $keyword")
launch {
val result = google(keyword)
println("Result for $keyword: $result")
}
}
}
In this example launch is a child of coroutineScope. This scope waits for the completion of all its children and in case of a crash the scope cancels all children. This structured behaviour safeguards that the suspend function will have no leaks if something goes wrong.
An exception other than CancellationException in a coroutine scope cancels its parent. This behaviour fosters stable coroutine hierarchies in the context of structured concurrency.
A CoroutineExceptionHandler may be used to replace try /catch blocks and handle exceptions in a centralised way.
val handler = CoroutineExceptionHandler { _, exception ->
println("Caught $exception")
}
If we want cancellation to be propagated only downwards we can use SupervisorJob or supervisorScope.
The example bellow demonstrates downwards cancelation propagation described above.
val supervisor = SupervisorJob()
with(CoroutineScope(supervisor)) {
val child1 = launch(handler) {
println("Child1 is failing")
throw AssertionError("child1 cancelled")
}
val child2 = launch {
child1.join()
println("Child1 cancelled: ${child1.isCancelled}")
println("Child2 isActive: $isActive")
try {
delay(Long.MAX_VALUE)
} finally {
println("Finally Child2 isActive: $isActive")
}
}
child1.join()
println("Cancelling supervisor")
supervisor.cancel()
child2.join()
}
The output is the following.
Child1 is failing
Caught java.lang.AssertionError: child1 cancelled
Cancelling supervisor
Child1 cancelled: true
Child2 isActive: true
Finally Child2 isActive: false
We launch child1 and child2 in the scope of a supervisor job. The failure of child1 did not affect the parent as expected. When we cancel the parent supervisor thought cancellation is propagated downwards and finally cancels child2.
A common problem in asynchronous programs is when the have to access a common state, a shared mutable state. A common approach to this is to create a class that controls the access to this shared resource.
Starting from our google() function imagine that we want to add a cache to avoid unnecessary network calls. Most probably a solution will include two mutable structures, the cache itself and a request queue.
private fun google(keyword: String): String { ... }
object Cache {
private val cache = mutableMapOf<String, String>()
private val requested = mutableSetOf<String>()
fun googleWithCache(keyword: String): String {
return cache[keyword] ?: if (requested.add(keyword)) {
val result = google(keyword)
cache.put(keyword, result)
requested.remove(keyword)
return result
} else {
sleep(2000) //wait and retry?
return googleWithCache(keyword)
}
}
}
The above (imagine the code was not so bad) is valid solution but it will quickly become more and more complicated as we scale.
In a coroutine world things can be different. The shared mutable state can be eliminated by using communication between our entities. Classes can be replaced with coroutines and finally the synchronization primitives needed to safeguard the shared state can be replaced with communication primitives.
Those communication primitives in Kotlin are called Channels and are still in experimental state. Note that experimental in Kotlin does not necessarily mean unstable, it means that the API is not finalised and may change in the future. A Channel can be conceived as a queue or as a communication bus. We can send or receive data over a channel.
Evolving the example above we will replace the Cache class with a coroutine. As we see in the code bellow a coroutine is defined as an extension to the coroutine scope. In our case it has an input stream of keywords and an output stream of results. Those are declared as ReceiveChannel of type String.
val mutex = Mutex()
val cache = mutableMapOf<String, String>()
fun CoroutineScope.cache(keywords: ReceiveChannel<String>): ReceiveChannel<String> = produce {
for(keyword in keywords) {
send(cache.getOrElse(keyword) {
val result = google(keyword)
mutex.withLock { cache[keyword] = result }
return@getOrElse result
})
}
}
For every keyword received through the channel we check if it exists in our cache. If it exists it sends the result to the channel. If not we make the network call and save it to the cache.
Note that the access to the shared resource cache is in a locked block defined by a Mutex. A Mutex is similar to a synchronized block on JVM. For now this approach should work. We will try to remove this when we evolve our example further.
The above cache channel implementation eliminated the need for a shared request queue. To see this working we will define a channel producer that sends a list of countries to the channel.
val countries = listOf(...)//a big list of countries
fun CoroutineScope.getCountries(): ReceiveChannel<String> = produce {
for (country in countries) send(country)
}
Finally our main function chains the above and passes the list of countries to the cache, which in turn sends the result to a channel.
fun main() = runBlocking {
val countries = getCountries()
val google = cache(countries)
for (i in 1..10){ //get ten results
println("Result $i: ${google.receive()}")
}
println("One more... ${google.receive()}")
}
Notice that even with more advanced features of coroutines (aka Channels) our expectation for a sequentially structured code is still met.
Evolving our code further we will try to also eliminate the cache shared resource. For that we will use actors.
An actor is an entity that combines a coroutine with a channel and encapsulates the state. Actors are handling specific types of action messages.
In our example we can define a retrieve and a store action on a cache. This can be declared under a root sealed class.
sealed class CacheAction(val keyword: String)
class RetrieveAction(keyword: String, val value: CompletableDeferred<String?>) : CacheAction(keyword)
class StoreAction(keyword: String, val value: String) : CacheAction(keyword)
An actor is a coroutine and thus is defined as an extension to the CoroutineScope.
fun CoroutineScope.cacheActor() = actor<CacheAction> {
val cache = mutableMapOf<String, String>() //state
for (msg in channel) {
when (msg) {
is RetrieveAction -> msg.value.complete(cache[msg.keyword])
is StoreAction -> cache[msg.keyword] = msg.value
}
}
}
Our cache coroutine can now be refactored to use the actor we created sending store and retrieve actions to the actor channel.
fun CoroutineScope.cache(keywords: ReceiveChannel<String>): ReceiveChannel<String> = produce {
val cache = cacheActor()
for(keyword in keywords) {
val value = CompletableDeferred<String?>()
cache.send(RetrieveAction(keyword, value))
val retrievedValue = value.await()
if(retrievedValue != null) {
send(retrievedValue!!)
} else {
val result = google(keyword)
cache.send(StoreAction(keyword, result))
send(result)
}
}
cache.close()
}
The main function remains the same as above. You can check the full code at Actors.kt
The concept of structured concurrency can be easily embedded in more complex use cases when we have objects with advanced lifecycles (e.g. an Android Activity). To do this we implement the CoroutineScope interface from our lifecycle aware class. The only thing we need to override is the coroutineContext property. That way we have a common context for all the coroutines in this scope in a controlled way. When the life of our object ends all we have to do is to cancel the job associated with the coroutineContext to keep things tidy.
class LifecycleAwareClass : CoroutineScope {
private val job = Job()
override val coroutineContext: CoroutineContext
get() = job + Dispatchers.Main
fun doSomethingImportant() {
launch {
//important process
}
}
fun onDestroy() { //or similar finalization method
//...
job.cancel()
}
}
Though marketed as such coroutines are not like threads. Using them correctly force us to rethink the way we structure our code. They intend to look like sequential code and hide the complicated stuff from the developer. That along with the fact that resource-wise are almost free is the main selling point for me. In any case, coroutines are the cool new thing in the JVM world.

And you know what? The whole idea behind suspending functions never failed those of us working with computers 😉
This article is based on a talk I gave at Kotlin Athens Meetup. The slides of the talk can be found at Speaker Deck. Any feedback, corrections or comments on this article or the presentation material are much appreciated.
